
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron (previously Deep Science), aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
This week in AI, a team of engineers at the University of Glasgow developed “artificial skin” that can learn to experience and react to simulated pain. Elsewhere, researchers at DeepMind developed a machine learning system that predicts where soccer players will run on a field, while groups from The Chinese University of Hong Kong (CUHK) and Tsinghua University created algorithms that can generate realistic photos — and even videos — of human models.
According to a press release, the Glasgow team’s artificial skin leveraged a new type of processing system based on “synaptic transistors” designed to mimic the brain’s neural pathways. The transistors, made from zinc-oxide nanowires printed onto the surface of a flexible plastic, connected to a skin sensor that registered changes in electrical resistance.

Image Credits: University of Glasgow
While artificial skin has been attempted before, the team claims that their design differed in that it used a circuit built into the system to act as an “artificial synapse” — reducing input to a spike in voltage. This sped up processing and allowed the team to “teach” the skin how to respond to simulated pain by setting a threshold of input voltage whose frequency varied according to the level of pressure applied to the skin.
The team sees the skin being used in robotics, where it could, for example, prevent a robotic arm from coming into contact with dangerously high temperatures.
Tangentially related to robotics, DeepMind claims to have developed an AI model, Graph Imputer, that can anticipate where soccer players will move using camera recordings of only a subset of players. More impressively, the system can make predictions about players beyond the view of the camera, allowing it to track the position of most — if not all — players on the field fairly accurately.
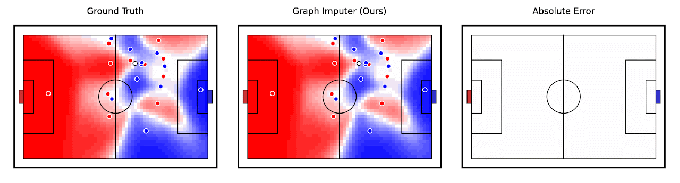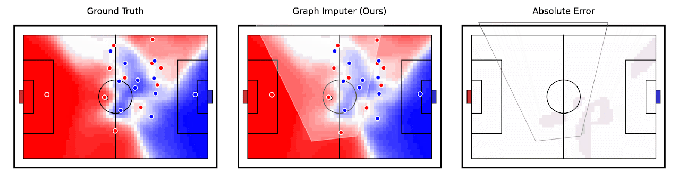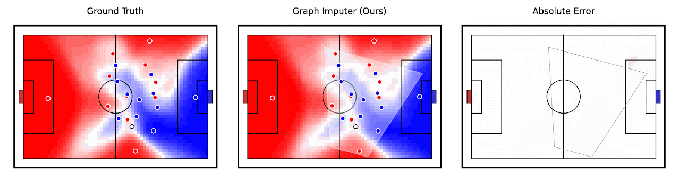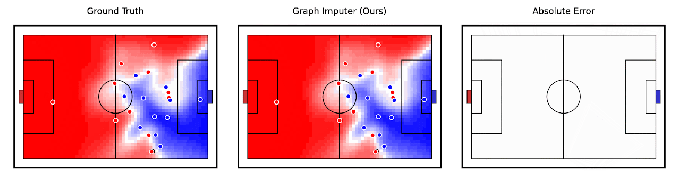
Image Credits: DeepMind
Graph Imputer isn’t perfect. But the DeepMind researchers say it could be used for applications like modeling pitch control, or the probability that a player could control the ball assuming it’s at a given location. (Several leading Premier League teams use pitch control models during games, as well as in pre-match and post-match analysis.) Beyond football and other sports analytics, DeepMind expects the techniques behind Graph Imputer will be applicable to domains like pedestrian modeling on roads and crowd modeling in stadiums.
While artificial skin and movement-predicting systems are impressive, to be sure, photo- and video-generating systems are progressing at a fast clip. Obviously, there’s high-profile works like OpenAI’s Dall-E 2 and Google’s Imagen. But take a look at Text2Human, developed by CUHK’s Multimedia Lab, which can translate a caption like “the lady wears a short-sleeve T-shirt with pure color pattern, and a short and denim skirt” into a picture of a person who doesn’t actually exist.
In partnership with the Beijing Academy of Artificial Intelligence, Tsinghua University created an even more ambitious model called CogVideo that can generate video clips from text (e.g., “a man in skiing,” “a lion is drinking water”). The clips are rife with artifacts and other visual weirdness, but considering they’re of completely fictional scenes, it’s hard to criticize too harshly.
Machine learning is often used in drug discovery, where the near-infinite variety of molecules that appear in literature and theory need to be sorted through and characterized in order to find potentially beneficial effects. But the volume of data is so large, and the cost of false positives potentially so high (it’s costly and time-consuming to chase leads) that even 99% accuracy isn’t good enough. That’s especially the case with unlabeled molecular data, by far the bulk of what’s out there (compared with molecules that have been manually studied over the years).
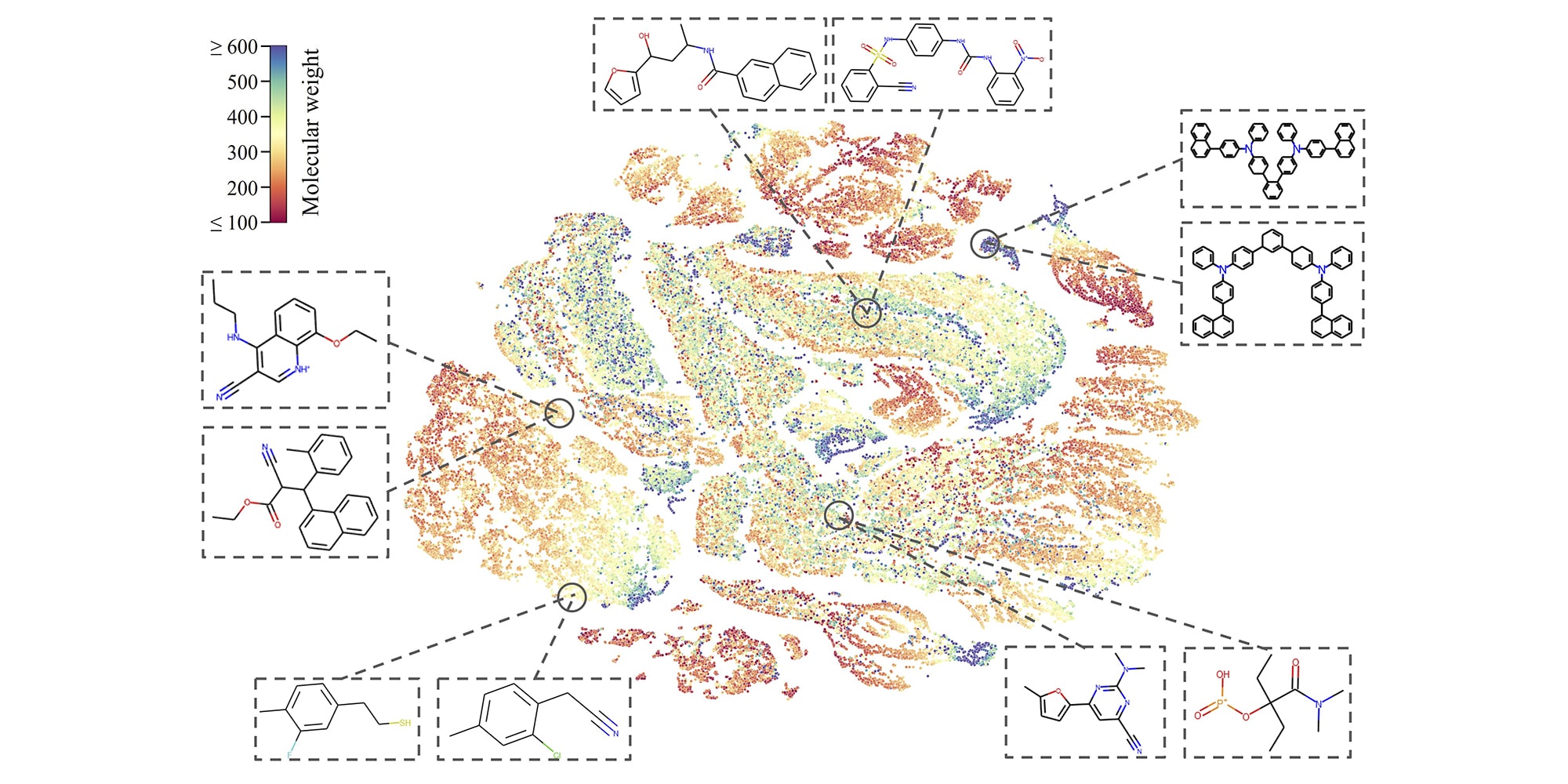
Image Credits: CMU
CMU researchers have been working to create a model to sort through billions of uncharacterized molecules by training it to make sense of them without any extra information. It does this by making slight changes to the (virtual) molecule’s structure, like hiding an atom or removing a bond, and observing how the resulting molecule changes. This lets its learn intrinsic properties of how such molecules are formed and behave — and led to it outperforming other AI models in identifying toxic chemicals in a test database.
Molecular signatures are also key in diagnosing disease — two patients may present similar symptoms, but careful analysis of their lab results shows that they have very different conditions. Of course that’s standard doctoring practice, but as data from multiple tests and analyses piles up, it gets difficult to track all the correlations. The Technical University of Munich is working on a sort of clinical meta-algorithm that integrates multiple data sources (including other algorithms) to differentiate between certain liver diseases with similar presentations. While such models won’t replace doctors, they will continue to help wrangle the growing volumes of data that even specialists may not have the time or expertise to interpret.
